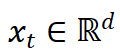AIxiv专栏是呆板之心宣布学术、技巧内容的栏目。从前数年,呆板之心AIxiv专栏接受报道了2000多篇内容,笼罩寰球各年夜高校与企业的顶级试验室,无效增进了学术交换与传布。假如你有优良的任务想要分享,欢送投稿或许接洽报道。投稿邮箱:[email protected];[email protected]回想 AGI 的暴发,从最初的 pre-training (model/data) scaling,到 post-training (SFT/RLHF) scaling,再到 reasoning (RL) scaling,找到准确的 scaling 维度一直是成绩的实质。2017 年宣布的 Transformer 架构相沿至今,离不开 Transformer 强盛的 “无损影象” 才能,固然也须要支付宏大的 KV 缓存价值。换句话说,Transformer 架构存在强盛的 memory scaling 才能。DeepSeek NSA 经由过程三种方法紧缩 “KV” 实现 sparse attention,但这只是一种能够任务但不优雅的折中计划。由于它在紧缩 Transfromer 的影象才能,以调换效力。另一方面,大略从 2023 年火到明天的线性序列建模方式(包含 linear attention 类,Mamba 系列,RWKV 系列)则是另一个极其,只保护一份牢固巨细 dxd 的 RNN memory state,而后加 gate,改更新规矩,但这种方法一直面对较低的机能下限,以是才会有种种混杂架构的同样能够任务但不优雅的折中计划。咱们以为,将来的模子架构必定存在两点特征:强盛的 memory scaling 才能 + 对于序列长度的低庞杂度。后者能够经由过程高效留神力机制实现,比方:linear 或许 sparse attention,是实现长序列建模的必备性子。而前者依然是一个有待摸索的主要课题,365娱乐官方网站咱们把给出的计划称为 “sparse memory”。这促使咱们计划永利APP最新下载地址了 MoM: Mixture-of-Memories,它让咱们从现在主流线性序列建模方式改 gate 跟 RNN 更新规矩的套路中跳脱出来,稀少且无穷制地扩展 memory 巨细。MoM 经由过程 router 散发 token(灵感来自 MoE)保护多个 KV memory,实现 memory 维度 scaling。每个 memory 又能够停止 RNN-style 盘算,以是团体存在对于序列长度线性的练习庞杂度,推理又是常数级庞杂度。别的,咱们又计划了 shared memory 跟 local memory 配合分辨处置全局跟部分信息。试验表示相称冷艳,尤其是在现在 linear 类方式后果欠好的 recall-instensive 义务上表示分外好,乃至在 1.3B 模子上曾经跟 Transformer 架构半斤八两。 论文地点:https://arxiv.org/abs/2502.13685代码地点:https://github.com/OpenSparseLLMs/MoM将来还汇集成在:https://github.com/OpenSparseLLMs/Linear-MoE模子权重开源在:https://huggingface.co/linear-moe-hub方式细节Linear Recurrent Memory对这局部内容,熟习线性序列建模的小搭档能够跳过了。输入
论文地点:https://arxiv.org/abs/2502.13685代码地点:https://github.com/OpenSparseLLMs/MoM将来还汇集成在:https://github.com/OpenSparseLLMs/Linear-MoE模子权重开源在:https://huggingface.co/linear-moe-hub方式细节Linear Recurrent Memory对这局部内容,熟习线性序列建模的小搭档能够跳过了。输入